Introduction
Overview
Perform tests using the Nuance Mix SaaS offering, specifically using the Speech Recognition (ASRaaS) and Natural Language (NLUaaS) services.
This tool uses a truth file (tab separated - tsv) and references to audio files (PCM/wav) to call, process, and evaluate the results, giving insight into the performance of your model(s).
Transactions are executed in real time against the services and then reports are generated: JSON raw data, and visually rendered HTML.
Eager to dive right in? Check out the QuickStart.
How It Works
Truth File (.tsv)
Provide a truth file with references to audio files to use when performing tests.
Data
The truth file (TSV) must include:
- Speaker profile identification
- Reference to the audio file - path; linear PCM 8kHz or 16kHz supported for now
- Transcription - text, note: adjudication map applies when scoring
- Annotation - in json form (e.g.
{"ENTITIY": "LITERAL|VALUE"}) - Intent
Rows
Each row in the TSV is exercised through the respective service based on your configuration (ie. ASR-only, NLU-only, ASR + NLU).
- The speaker profile ID described is used when executing ASR.
- Transcription applies to ASR, and is used for NLU if NLU-only configuration.
- Annotation and Intent are leveraged in evaluation of NLU.
Execution Considerations
When executing tests, they are based on a configuration.
Various configurations leverage the truth file in different ways:
- ASR-only (
nlu: null)- will rely on the speaker profile, audio file and transcription as input
- NLU-only (
asr: null)- will rely on the transcription as input
- ASR and NLU
- will rely on the speaker profile and audio file as input to ASR; intent and annotation to NLU
Scoring and Test Results
Once execution is complete the results are scored and reports are created.
The scored results include:
- transactions
- count - total number of transactions
- passed - how many passed
- failed - how many failed
- server_failed - number failed due to server
- tool_failed - number failed due to tool
- error_rate - rate of errors
- transcriptions
- count - total number of transcriptions
- passed - how many passed
- failed - how many failed
- word_error_rate - the rate of errors
- substitutions - number of substitutions
- casing - number of casing differences
- insertions - number of insertion differences
- deletion - number of deletions
- nlu + nlu_stats & nlu_grammar
- count - total nlu transactions
- passed - how many passed
- failed - how many failed
- error_rate - rate of errors
- intents
- count - total scoring tasks for intent testing
- passed - how many passed
- failed - how many failed
- error_rate -rate of errors
- confusion_matrix - decipher which intents are being confused (stat model and grammar)
- slots
- count - total scoring tasks for entity mentions
- passed - how many passed
- failed - how many failed
- error_rate - rate of errors
- slots[].. - each of the slots and their respective metrics
- rows
- index - item in tsv
- perfect - test complete success
- error - test error
- audio - reference to audio path leveraged
- word_error_rate
- slot_error_rate
- ....
- transcription (expected, actual, score),
- intent (expected, actual, score),
- slots (passed, failed, slots[]..)
Report & Raw Results
Final test results are compiled in raw JSON form, and accompanied by a rendered HTML report for convenience.
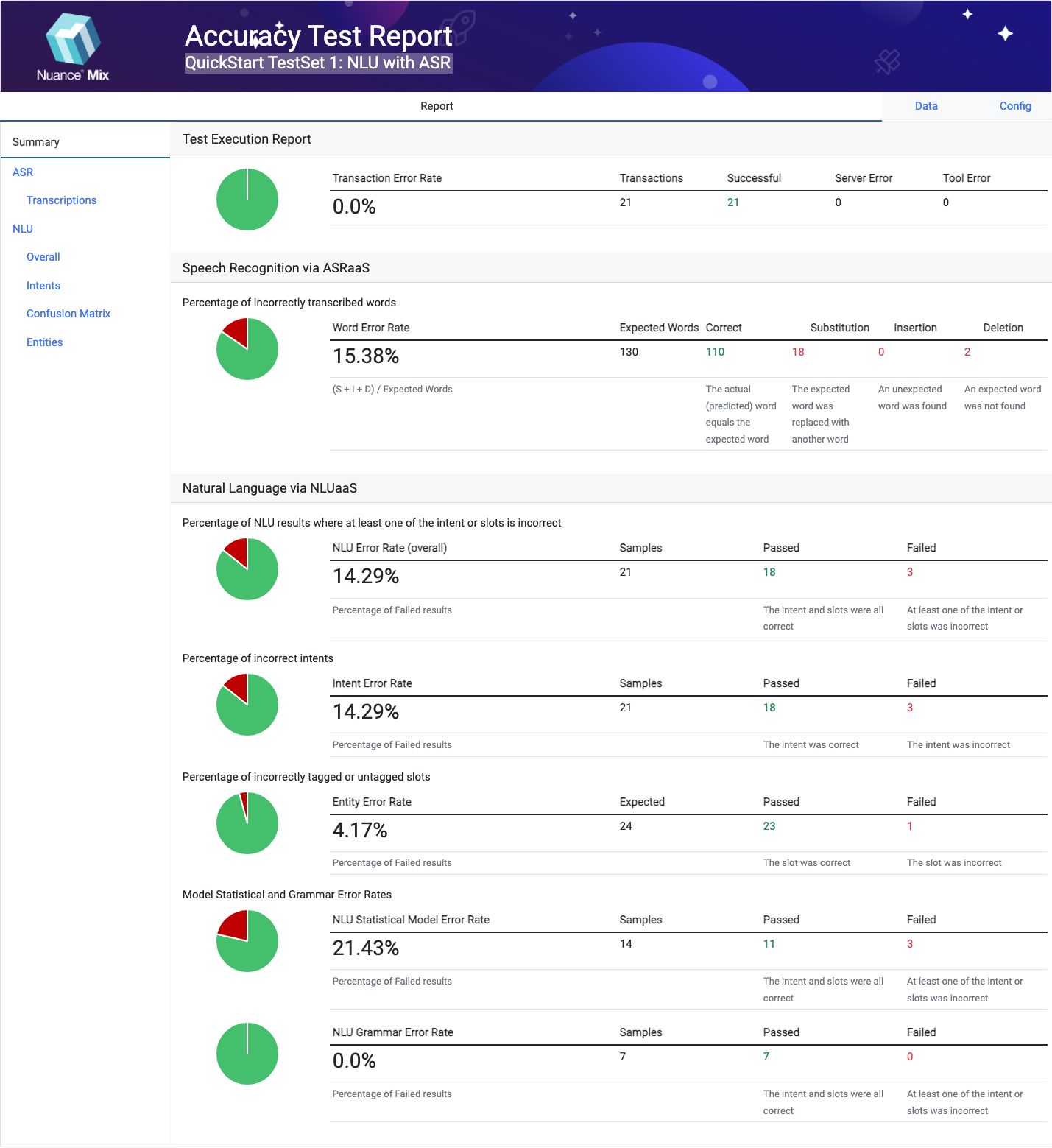
See Using the Report for more about the reports.
For information about the raw json output: see overview.json.
Errors
If errors arrise, the tool will mark those results as such:
- Tool Errors
- Server Errors
See Errors for more details.
Disclaimer
Performing accuracy tests successfully involves knowledge in how language AI technologies operate.
To compensate for acceptable formatting differences, the tool offers an adjudication map, which is domain-specific and requires customization.
Please consult your Nuance Technical Expert for assistance in this area.
Known Limitations
Current limitations will be addressed in future releases.
The following features are currently not supported.
They are specifically noted as they apply based on complexity of tests being performed.
- Scoring for...
- multiple entities (including contiguous entities)
- hierarchical entities (hasA)
- operators, e.g. and/or/not